
Schlechte Datenpraktiken noch weit verbreitet
KI weltweit auf dem Durchmarsch, Deutschland gehört zu den Nachzüglern
Herausforderungen, ROI, Kosten & Co: Wie wird KI in Unternehmen wirklich eingesetzt?
Fivetran und Vanson Bourne präsentieren umfangreiche Studie
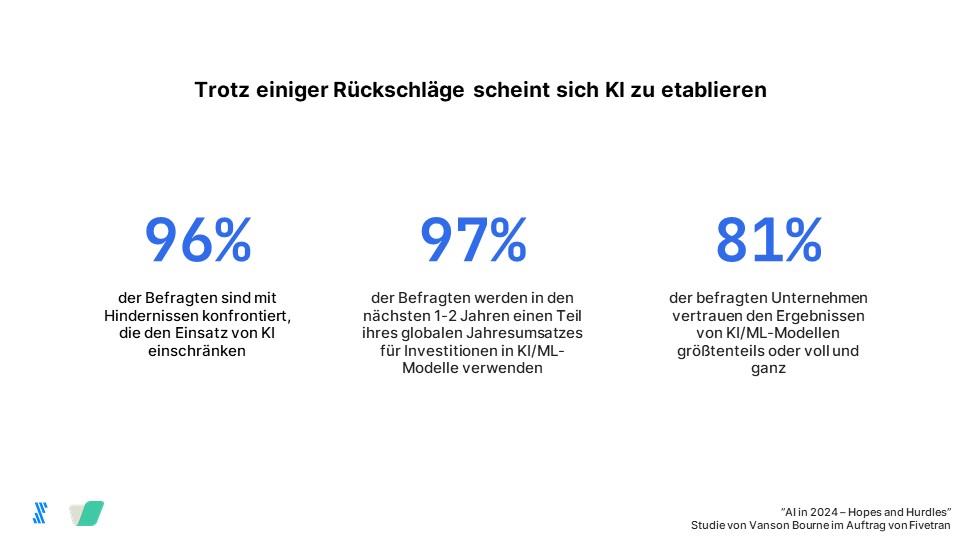
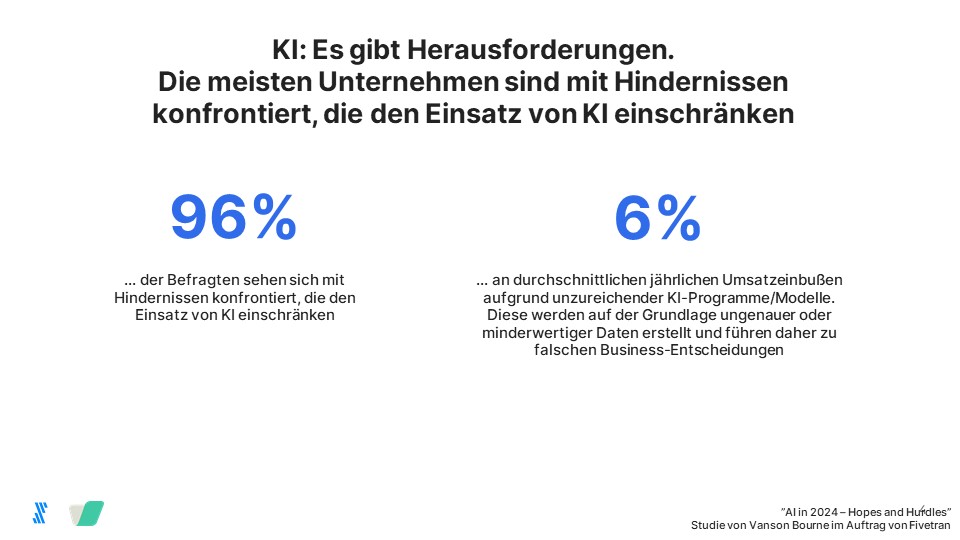
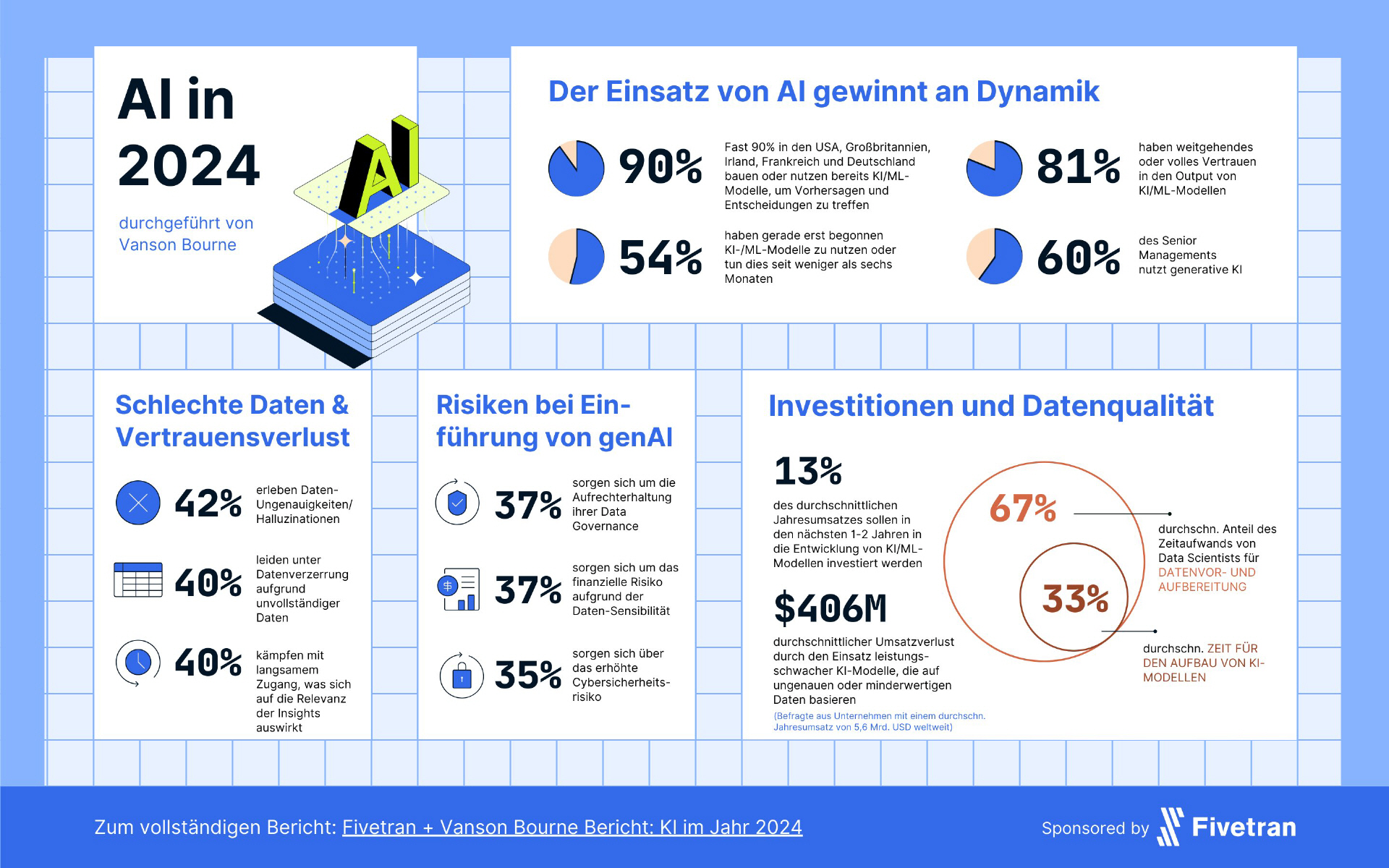
Fivetran, Anbieterin für Data Movement, präsentiert die Ergebnisse einer Umfrage, die zeigt: 81 Prozent der befragten Unternehmen vertrauen ihren KI/ML-Ergebnissen, obwohl sie zugeben, fundamentale Daten-Ineffizienzen zu haben. Sie verlieren im Durchschnitt 6 Prozent ihres weltweiten Jahresumsatzes, bzw. 406 Millionen US-Dollar bei einem durchschnittlichen Jahresumsatz von 5,6 Milliarden US-Dollar der befragten Unternehmen. Die Ursache sind unzureichende KI-Modelle, die mit ungenauen oder minderwertigen Daten erstellt werden und dadurch zu falschen Geschäftsentscheidungen führen.
Schlusslicht Deutschland
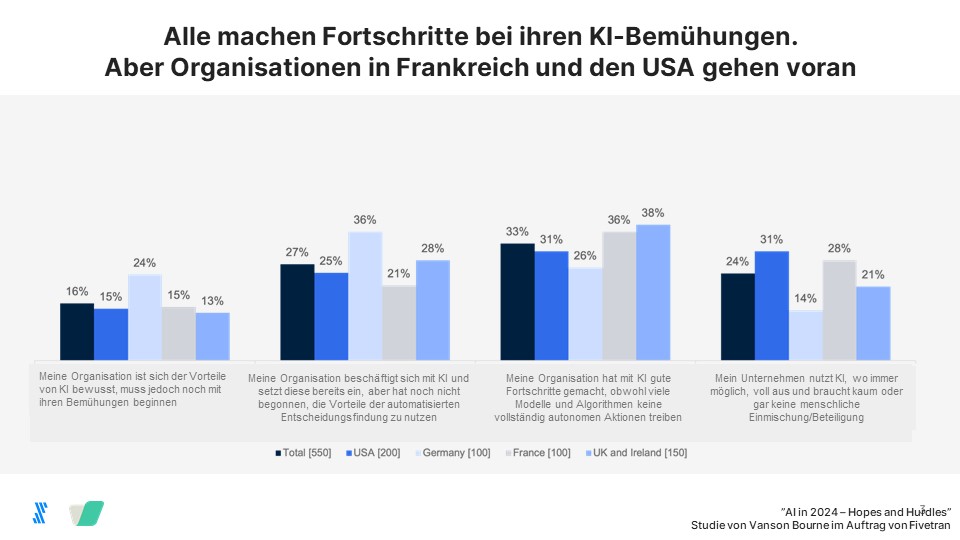
Deutsche Unternehmen stehen noch eher am Anfang der KI-Nutzung (60 Prozent), während das in den USA nur noch 39 Prozent, in Frankreich sogar nur 36 Prozent sind. Dementsprechend sehen sich Unternehmen dort als fortgeschritten: 31 Prozent (USA) bzw. 28 Prozent (Frankreich) nutzen KI, die keine oder kaum menschliche Eingriffe erfordert, wo immer das möglich ist. In Deutschland sind das gerade einmal 14 Prozent. Insgesamt setzen fast neun von zehn Unternehmen (89 Prozent) KI-/ML-Methoden für die Erstellung von Modellen ein, die automatisch Vorhersagen und Entscheidungen treffen können. 80 Prozent der Unternehmen in den USA und 75 Prozent in Frankreich tun das schon mindestens sechs Monate, in Deutschland sagen das lediglich 44 Prozent von sich.
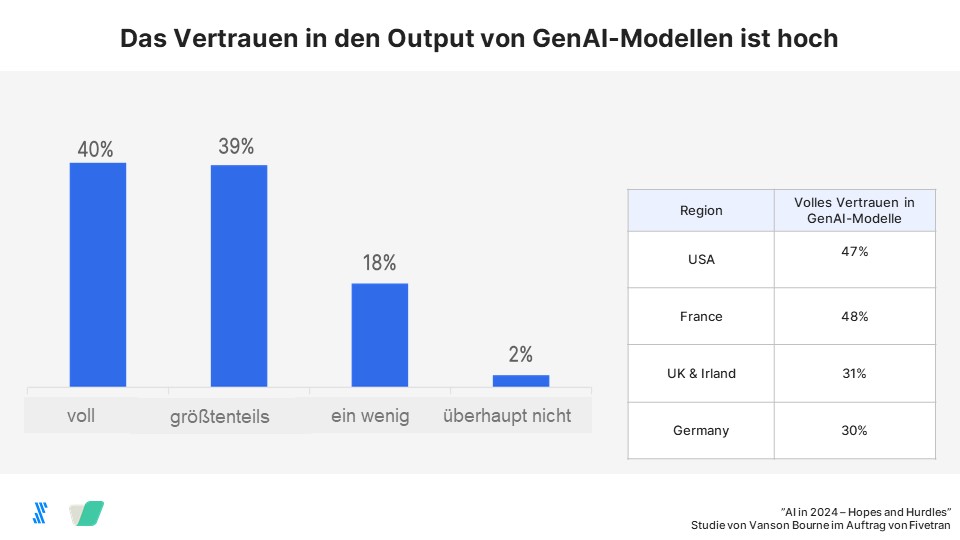
Auch das Vertrauen in die Ergebnisse einer KI sind in Deutschland gering: Während 30 Prozent der deutschen Unternehmen den Ergebnissen von Generativer KI voll und ganz vertrauen, sagen das 47 Prozent der US-amerikanischen und 48 Prozent der französischen Unternehmen.
Die unabhängigen Marktforschungsspezialisten Vanson Bourne befragten in einer Online-Umfrage 550 Teilnehmer aus Unternehmen mit 500 oder mehr Mitarbeitenden in den USA, Großbritannien, Irland, Frankreich und Deutschland. 100 Teilnehmer kamen aus Deutschland. Die Umfrage ergab, dass fast neun von zehn Unternehmen KI-/ML-Methoden einsetzen, um Modelle für die autonome Entscheidungsfindung zu erstellen. 97 Prozent werden in den nächsten ein bis zwei Jahren in generative KI investieren. Gleichzeitig haben die Unternehmen Probleme mit Datenungenauigkeiten und -Halluzinationen sowie Bedenken hinsichtlich Data Governance und Datensicherheit. US-Unternehmen, die Large Language Models (LLMs) nutzen, berichten in 50 Prozent der Fälle von Datenungenauigkeiten und -Halluzinationen.
"Die schnelle Verbreitung von generativer KI spiegelt einen weit verbreiteten Optimismus und eine Zuversicht in den Unternehmen wider. Aber unter der Oberfläche gibt es immer noch grundlegende Datenprobleme, die Unternehmen daran hindern, ihr volles Potenzial auszuschöpfen", erklärt Taylor Brown, Mitbegründer und COO von Fivetran. "Unternehmen müssen ihre Datenintegrations- und -Governance-Grundlagen stärken, um zuverlässigere KI-Ergebnisse zu erzielen und finanzielle Risiken zu minimieren."
Unterschiedliche "KI-Realitäten" in verschiedenen Berufsrollen
Etwa jedes vierte Unternehmen (24 Prozent) gab an, ein fortgeschrittenes Stadium der KI-Nutzung erreicht zu haben, in dem es die Vorteile der KI voll ausschöpft und nur noch wenig oder gar nicht mehr auf menschliche Eingriffe angewiesen ist. Allerdings gibt es erhebliche Meinungsverschiedenheiten zwischen den Befragten: Technische Führungskräfte, die KI-Modelle entwickeln und betreiben, sind von der KI-Reife ihrer Unternehmen weniger überzeugt. Von ihnen bezeichnen nur 22 Prozent sie als "fortgeschritten", verglichen mit 30 Prozent der nicht-technischen Mitarbeitenden. Anders bei generativer KI: Ihr vertrauen 63 Prozent der nicht-technischen Mitarbeitenden vollständig, bei den technischen Führungskräften sind es 42 Prozent.
Eine weitere Uneinigkeit besteht zwischen den Datenexperten auf unterschiedlichen Führungsebenen eines Unternehmens: Während die in Junior-Positionen veraltete IT-Infrastrukturen als größtes Hindernis für die Entwicklung von KI-Modellen sehen (49 Prozent), sehen leitende Kollegen das Hauptproblem darin, dass sich Mitarbeitende mit den richtigen Fähigkeiten auf andere Projekte konzentrieren (51 Prozent). Tatsächlich sind diese gezwungen, ihre Ressourcen für manuelle Datenprozesse wie die Bereinigung von Daten und die Reparatur defekter Datenpipelines zu nutzen. Unternehmen geben zu, dass ihre Data Scientists den Großteil (67 Prozent) ihrer Zeit mit der Aufbereitung von Daten verbringen, anstatt KI-Modelle zu erstellen.
Schlechte Datenpraktiken sind immer noch weit verbreitet
Die Ursache für das vergeudete Potenzial von Datenspezialisten und die unzureichende Performance von KI-Programmen ist dieselbe: unzugängliche, unzuverlässige und falsche Daten. Wie groß das Problem ist, zeigt die Tatsache, dass die meisten Unternehmen Schwierigkeiten haben, auf alle Daten zuzugreifen, die für die Ausführung von KI-Programmen benötigt werden (69 Prozent) und diese in ein brauchbares Format zu bringen (68 Prozent).
Neue Ansätze bei generativer KI haben weitere Komplikationen mit sich gebracht: 42 Prozent der Befragten hatten schon mit Datenhalluzinationen zu tun. Diese können zu schlechten Entscheidungen führen, da die Informationsbasis mangelhaft ist. Sie verringern das Vertrauen in LLMs oder die Bereitschaft der Mitarbeitenden, das Tool zu nutzen. Zudem rauben sie viel Zeit für das Auffinden und Korrigieren der Daten. Angesichts der Tatsache, dass 60 Prozent der leitenden Angestellten generative KI nutzen und für strategische Entscheidungen verantwortlich sind, werden Probleme mit der Qualität und Vertrauenswürdigkeit der Daten noch verstärkt.
Data Governance als Schlüsselbereich für den Einsatz von KI
Die Befürchtungen hinsichtlich des Einsatzes generativer KI bleiben ebenfalls bestehen, wobei "die Aufrechterhaltung der Data Governance" und "finanzielle Risiken aufgrund der Sensibilität der Daten" die größten Bedenken der Unternehmen sind (37 Prozent). Solide Data-Governance-Grundlagen sind besonders wichtig für Unternehmen, die entweder eigene generative-KI-Modelle entwickeln oder eine Kombination aus bestehenden externen sowie intern entwickelten Modellen verwenden wollen. Da jedoch die Mehrheit (67 Prozent) der Befragten den Einsatz neuer Technologien plant, um grundlegende Datenbewegungen, Governance- und Sicherheitsfunktionen zu stärken, gibt es Grund zum Optimismus. (Fivetran: ra)
eingetragen: 01.04.24
Newsletterlauf: 21.05.24
Fivetran: Kontakt und Steckbrief
Fivetran automatisiert alle Arten von Data Movement im Zusammenhang mit Cloud-Datenplattformen. Das gilt vor allem für die zeitaufwendigsten Teile des ELT-Prozesses (Extract, Load, Transform) - von der Extraktion von Daten über das Handling von Schema-Drifts bis hin zu Daten-Transformationen. Damit können sich Data Engineers auf wichtigere Projekte konzentrieren, ohne sich um die Data Pipelines kümmern zu müssen. Mit einer Up-Time von 99,9 Prozent und sich selbst reparierenden Pipelines ermöglicht Fivetran Hunderten von führenden Marken weltweit, darunter Autodesk, Lionsgate und Morgan Stanley, datengestützte Entscheidungen zu treffen und so ihr Unternehmenswachstum voranzutreiben. Fivetran hat seinen Hauptsitz in Oakland, Kalifornien, und verfügt über Niederlassungen auf der ganzen Welt.
Der deutschsprachige Markt wird aus dem Büro in München betreut. Zu den Kunden in Deutschland zählen DOUGLAS, Hermes, Lufthansa, Siemens, VW Financial Services und Westwing. Weitere Informationen unter www.fivetran.com.
Kontaktdaten
Fivetran Germany GmbH
Franz-Joseph-Str. 11
80801 München
E-Mail: hallo[at]fivetran.com
Webseite: https://fivetran.com/de
Dieses Boilerplate ist eine Anzeige der Firma Fivetran.
Sie zeichnet auch für den Inhalt verantwortlich.
Lesen Sie mehr:
Automatisierte Datenintegration
Risiken für Produktionssysteme eliminiert
Fivetran und dbt Labs fusionieren
Verantwortung für Datenschutz und Compliance
Modernisierung der Dateninfrastruktur
Datentransformation transparenter zu gestalten
Datengrundlagen für Analysen und KI
Fivetran präsentiert erweitertes "Connector SDK"
Compliance als größte Herausforderung
Fivetran: Monica Ohara mit umfassender Erfahrung
Fivetran: Vereinbarung zur Übernahme von Census
Managed Data Lake Service auf Microsoft Azure
KI erfordert riesige Mengen hochwertiger Daten
Datenintegration für Unternehmen jeder Größe
Fivetran vereinfacht Datenintegration
Nahtlose Replikation großer Datensätze
Die Datenkultur hat sich grundlegend gewandelt
Data Governance und Datensicherheit
Fivetran weiter auf der Erfolgsspur
Cloud-Deployment für Fivetran-Plattform
Fivetran erweitert Partnerschaft mit Snowflake
Datenautobahn ohne Stau für die Logistik
Nutzung von KI- und Generative-KI-Technologien
Data Lake Management automatisiert und vereinfacht
Daten sind Basis für alle Formen der KI
Schlechte Datenpraktiken noch weit verbreitet
Datenbasierte Entscheidungen treffen
Datenaustausch im Unternehmen automatisieren
Reduzierte Latenzzeiten und Kosten
25 Jahre Erfahrung im SaaS-Umfeld
Fivetran sorgt für Business Insights
Kontrollierte, benutzerfreundliche Repositories
Aufbau einer soliden Data-Lake-Grundlage
Cloud Data Lake, Lakehouse oder Warehouse
Skalierbare Konnektoren und Destinationen
Fivetran als Launch-Partnerin
Prozess zur Datenintegration in BigQuery
Weniger Kosten für Neukundengewinnung
Inspirierende Führungspersönlichkeit
Anbindung an praktisch jede SaaS-Anwendung
Unterstützung von Amazon S3
Fivetran setzt Wachstum fort
Daten in Cloud- & On-Premise-Umgebungen
Fivetran: Führungsteam ausgebaut
Data Act könnte schon 2024 in Kraft treten
Mit Cloud-Architektur zum "Master of Data"
Vorteile automatisierter Datenintegration
Schwierigkeiten bei der Bereitstellung der Daten
Verantwortung für Datenschutz und Compliance
Starke Dateninfrastruktur muss Priorität werden
Datengrundlagen für Analysen und KI
Fivetran präsentiert erweitertes "Connector SDK"
Compliance als größte Herausforderung
Fivetran: Monica Ohara mit umfassender Erfahrung
Fivetran: Vereinbarung zur Übernahme von Census
Managed Data Lake Service auf Microsoft Azure
KI erfordert riesige Mengen hochwertiger Daten
Datenintegration für Unternehmen jeder Größe
Fivetran vereinfacht Datenintegration
Nahtlose Replikation großer Datensätze
Die Datenkultur hat sich grundlegend gewandelt
Data Governance und Datensicherheit
Fivetran weiter auf der Erfolgsspur
Cloud-Deployment für Fivetran-Plattform
Fivetran erweitert Partnerschaft mit Snowflake
Datenautobahn ohne Stau für die Logistik
Nutzung von KI- und Generative-KI-Technologien
Data Lake Management automatisiert und vereinfacht
Daten sind Basis für alle Formen der KI
Schlechte Datenpraktiken noch weit verbreitet
Datenbasierte Entscheidungen treffen
Datenaustausch im Unternehmen automatisieren
Reduzierte Latenzzeiten und Kosten
25 Jahre Erfahrung im SaaS-Umfeld
Fivetran sorgt für Business Insights
Kontrollierte, benutzerfreundliche Repositories
Aufbau einer soliden Data-Lake-Grundlage
Cloud Data Lake, Lakehouse oder Warehouse
Skalierbare Konnektoren und Destinationen
Fivetran als Launch-Partnerin
Prozess zur Datenintegration in BigQuery
Weniger Kosten für Neukundengewinnung
Inspirierende Führungspersönlichkeit
Anbindung an praktisch jede SaaS-Anwendung
Unterstützung von Amazon S3
Fivetran setzt Wachstum fort
Daten in Cloud- & On-Premise-Umgebungen
Fivetran: Führungsteam ausgebaut
Data Act könnte schon 2024 in Kraft treten
Mit Cloud-Architektur zum "Master of Data"
Vorteile automatisierter Datenintegration
Schwierigkeiten bei der Bereitstellung der Daten